해당 내용은 T1012 스터디에 나온 내용과 '테라폼으로 시작하는 IaC' 책을 기준으로 정리 했습니다
3.9 반복문
list 형태의 값 목록이나 Key-Value 형태의 문자열 집합인 데이터가 있는 경우 동일한 내용에 대해 테라폼 구성 정의를 반복적으로 하지 않고 관리할 수 있다.
count
반복문, 정수 값만큼 리소스나 모듈을 생성
- 리소스 또는 모듈 블록에 count 값이 정수인 인수가 포함된 경우 선언된 정수 값만큼 리소스나 모듈을 생성하게 된다.
- count에서 생성되는 참조값은 count.index이며, 반복하는 경우 0부터 1씩 증가해 인덱스가 부여된다.
# 실습 환경 구성
mkdir 3.9 && cd 3.9
# main.tf 생성
resource "local_file" "abc" {
count = 5
content = "abc"
filename = "${path.module}/abc.txt"
}
output "filecontent" {
value = local_file.abc.*.content
}
output "fileid" {
value = local_file.abc.*.id
}
output "filename" {
value = local_file.abc.*.filename
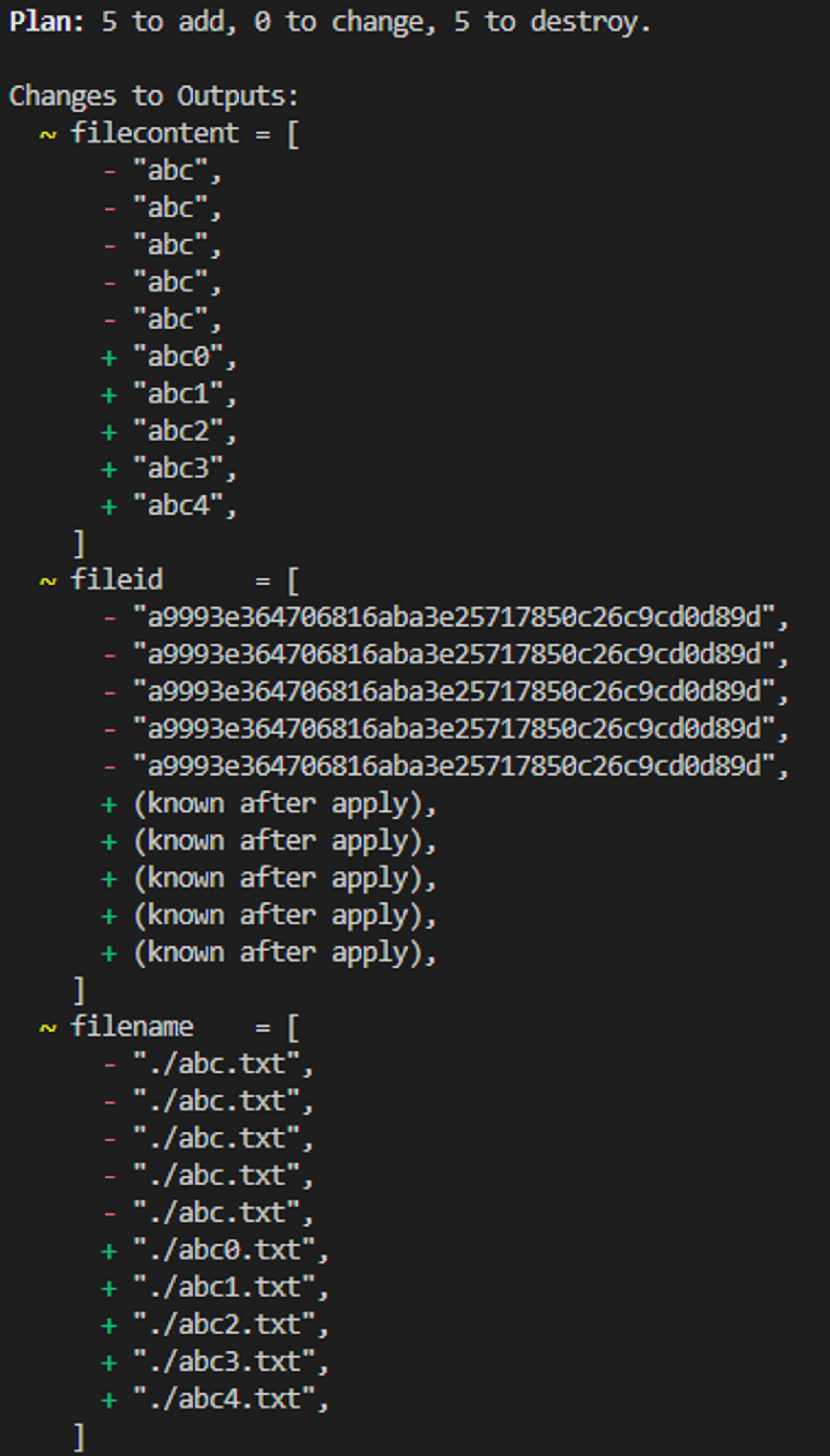
}terraform init && terraform apply -auto-approve
terraform state show local_file.abc[0]
terraform state show local_file.abc[4]count 로 5번 작업을 하겠지만 abc.txt 라는 파일은 한개밖에 없다


# main.tf 수정
resource "local_file" "abc" {
count = 5
content = "abc${count.index}"
filename = "${path.module}/abc${count.index}.txt"
}
output "fileid" {
value = local_file.abc.*.id
}
output "filename" {
value = local_file.abc.*.filename
}
output "filecontent" {
value = local_file.abc.*.content
}


- 여러 리소스나 모듈의 count로 지정되는 수량이 동일해야 하는 상황이 있다.
이 경우 count에 부여되는 정수 값을 외부 변수에 식별되도록 구성할 수 있다.
# list 형태의 배열을 활용한 반복문 동작 구성
## main.tf 파일 수정
variable "names" {
type = list(string)
default = ["a", "b", "c"]
}
resource "local_file" "abc" {
count = length(var.names)
content = "abc"
# 변수 인덱스에 직접 접근
filename = "${path.module}/abc-${var.names[count.index]}.txt"
}
resource "local_file" "def" {
count = length(var.names)
content = local_file.abc[count.index].content
# element function 활용
filename = "${path.module}/def-${element(var.names, count.index)}.txt"
}
# 실행
terraform apply -auto-approve
terraform state list
# local_file.abc와 local_file.def는 var.name에 선언되는 값에 영향을 받아
# 동일한 갯수만큼 생성하게 된다.
# local_file.def의 경우 local_file.abc와 개수가 같아야 content에 선언되는 인수 값에 오류가 없을 것이므로
# 서로 참조되는 리소스와 모듈의 반복정의에 대한 공통의 영향을 주는 변수로 관리할 수 있다.

- count로 생성되는 리소스의 경우 <리소스 타입>.<이름>[<인덱스 번호>]
모듈의 경우 module.<모듈 이름>[<인덱스 번호>]로 해당 리소스의 값을 참조한다.
count 주의사항
- 모듈 내에 count 적용이 불가능한 선언이 있는데
예를 들어 provider 블록 선언부가 포함되어 있는 경우에는 count 적용이 불가능하다 → provider 분리 - 그리고 외부 변수가 list 타입인 경우 중간에 값이 삭제되면 인덱스가 줄어들어
의도했던 중간 값에 대한 리소스만 삭제되는 것이 아니라 이후의 정의된 리소스들도 삭제되고 재생성된다.
즉 ["a","b","c"] 인 0..2 의 list 형식인 경우
~.a [0]
~.b [1]
~.c [2]
테라폼 코드상 "b"를 제거 했을때
["a","c"] 인 0,1 가 되어 "c"를 제거 하고, "c"를 생성 해버리는 상황이 발생 한다
~.a [0]
~.c [1]
* list 내부의 data가 중점이 아니라 index 를 중점으로 인지 해야함
중복이 가능한 자원의 경우 그냥 만들어 지겠지만
중복이 불가능한 자원의 경우 list가 꼬여 잘못 지워지는 상황이 발생for_each
반복문, 선언된 key 값 개수만큼 리소스를 생성
- 리소스 또는 모듈 블록에서 for_each에 입력된 데이터 형태가 map 또는 set이면,
선언된 key 값 개수만큼 리소스를 생성하게 된다.
- for_each가 설정된 블록에서는 each 속성을 사용해 구성을 수정할 수 있다
- each.key : 이 인스턴스에 해당하는 map 타입의 key 값
- each.value : 이 인스턴스에 해당하는 map의 value 값
# main.tf 수정
resource "local_file" "abc" {
for_each = {
a = "content a"
b = "content b"
}
content = each.value
filename = "${path.module}/${each.key}.txt"
}

# main.tf 파일 수정
## local_file.abc는 변수의 map 형태의 값을 참조
## local_file.def의 경우 local_file.abc 도한 결과가
## map으로 반환되므로 다시 for_each 구문을 사용할 수 있다
variable "names" {
default = {
a = "content a"
b = "content b"
c = "content c"
}
}
resource "local_file" "abc" {
for_each = var.names
content = each.value
filename = "${path.module}/abc-${each.key}.txt"
}
resource "local_file" "def" {
for_each = local_file.abc
content = each.value.content
filename = "${path.module}/def-${each.key}.txt"
}
- key 값은 count의 index와는 달리 고유하므로
중간에 값을 삭제한 후 다시 적용해도 삭제한 값에 대해서만 리소스를 삭제한다.
# main.tf 수정
## count와 유사하게 a,b,c 중 중간 값 b을 삭제 후 확인
variable "names" {
default = {
a = "content a"
c = "content c"
}
}
resource "local_file" "abc" {
for_each = var.names
content = each.value
filename = "${path.module}/abc-${each.key}.txt"
}
resource "local_file" "def" {
for_each = local_file.abc
content = each.value.content
filename = "${path.module}/def-${each.key}.txt"
}
for
복합 형식 값의 형태를 변환하는 데 사용 (for_each와 다름)
- list 값의 포맷을 변경하거나 특정 접두사 prefix를 추가할 수도 있고
output에 원하는 형태로 반복적인 결과를 표현할 수 도 있다.- list 타입의 경우 값 또는 인덱스와 값을 반환
- map 타입의 경우 키 또는 키와 값에 대해 반환
- set 타입의 경우 키 값에 대해 반환
# main.tf 파일 수정
## list의 내용을 담는 리소스를 생성
## var.name의 내용이 결과 파일에 content로 기록됨
variable "names" {
default = ["a", "b", "c"]
}
resource "local_file" "abc" {
content = jsonencode(var.names) # 결과 : ["a", "b", "c"]
filename = "${path.module}/abc.txt"
- var.names 값을 대문자로 변경하기
# main.tf 파일 수정
## content의 값 정의에 for 구문을 사용하여 내부 값을 일괄적으로 변경
variable "names" {
default = ["a", "b", "c"]
}
resource "local_file" "abc" {
content = jsonencode([for s in var.names : upper(s)]) # 결과 : ["A", "B", "C"]
filename = "${path.module}/abc.txt"
}
- for 구문을 사용하는 몇 가지 규칙은 다음과 같다
- list 유형의 경우 반환 받는 값이 하나로 되어 있으면 값을, 두 개의 경우 앞의 인수가 인덱스를 반환하고 뒤의 인수가 값을 반환
- map 유형의 경우 반환 받는 값이 하나로 되어 있으면 키를, 두 개의 경우 앞의 인수가 키를 반환하고 뒤의 인수가 값을 반환
- 결과 값은 for 문을 묶는 기호가 **[ ]**인 경우 tuple로 반환되고 **{ }**인 경우 object 형태로 반환
- object 형태의 경우 키와 값에 대한 쌍은 ⇒ 기호로 구분
- { } 형식을 사용해 object 형태로 결과를 반환하는 경우 키 값은 고유해야 하므로 값 뒤에 그룹화 모드 심볼(…)를 붙여서 키의 중복을 방지(SQL의 group by 문 또는 Java의 MultiValueMap과 같은 개념)
- if 구문을 추가해 조건 부여 가능
# main.tf 수정
## list 유형에 대한 for 구문 처리의 몇 가지 예
variable "names" {
type = list(string)
default = ["a", "b"]
}
output "A_upper_value" {
value = [for v in var.names : upper(v)]
}
output "B_index_and_value" {
value = [for i, v in var.names : "${i} is ${v}"]
}
output "C_make_object" {
value = { for v in var.names : v => upper(v) }
}
output "D_with_filter" {
value = [for v in var.names : upper(v) if v != "a"]
}# 실행
terraform apply -auto-approve
# 확인
terraform console
>
-----------------
var.names
[for v in var.names : upper(v)]
[for i, v in var.names : "${i} is ${v}"]
{ for v in var.names : v => upper(v) }
[for v in var.names : upper(v) if v != "a"]
exit
-----------------

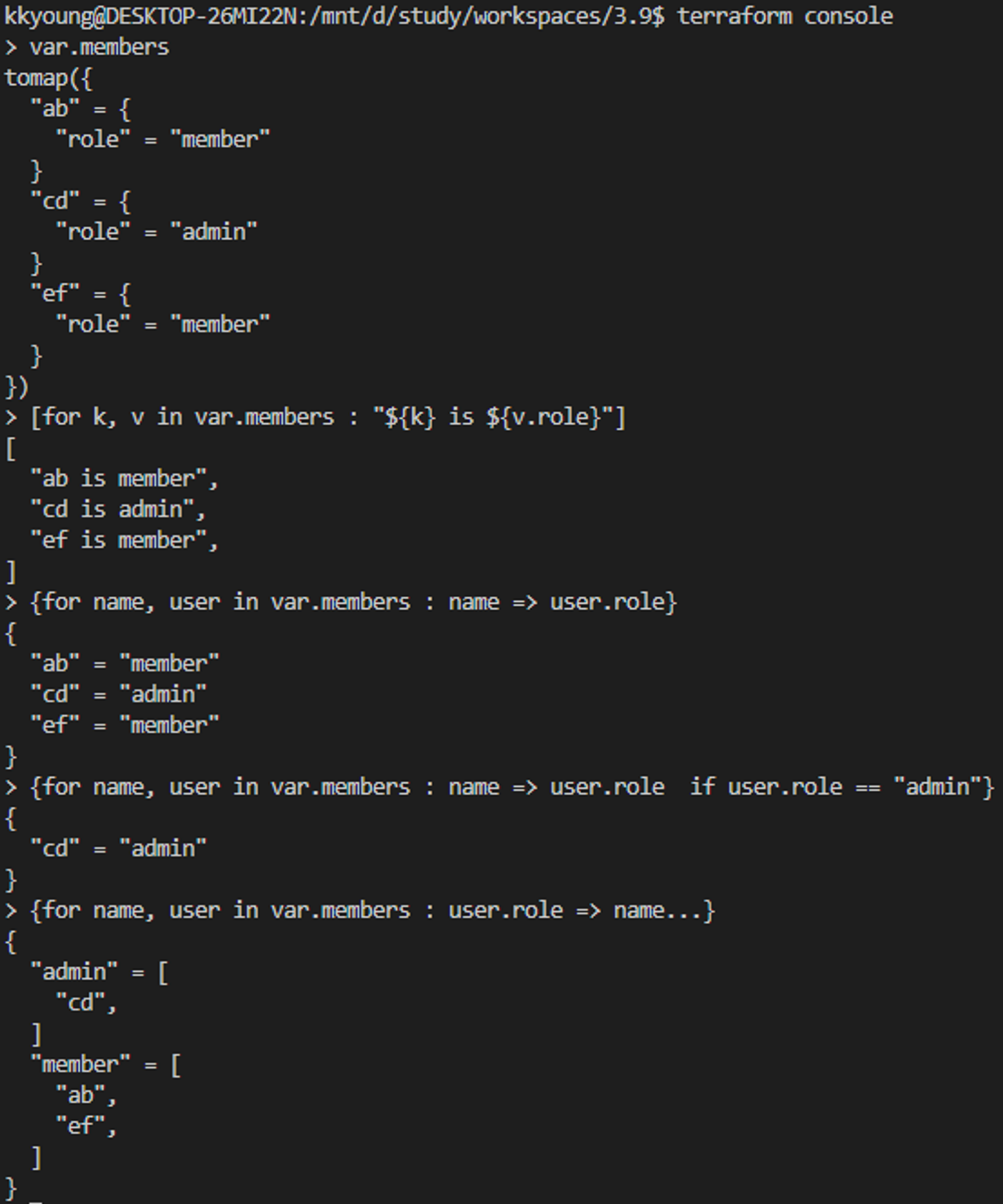
# map 유형에 대한 for 구문 처리의 몇 가지 예를 확인
## main.tf 수정
variable "members" {
type = map(object({
role = string
}))
default = {
ab = { role = "member", group = "dev" }
cd = { role = "admin", group = "dev" }
ef = { role = "member", group = "ops" }
}
}
output "A_to_tupple" {
value = [for k, v in var.members : "${k} is ${v.role}"]
}
output "B_get_only_role" {
value = {
for name, user in var.members : name => user.role
if user.role == "admin"
}
}
output "C_group" {
value = {
for name, user in var.members : user.role => name...
}
}
dynamic
리소스 내부 속성 블록을 동적인 블록으로 생성
- count 나 for_each 구문을 사용한 리소스 전체를 여러 개 생성하는 것 이외도 리소스 내에 선언되는 구성 블록을 다중으로 작성해야 하는 경우가 있다.
- 예를 들면 AWS Security Group 리소스 구성에 ingress, egress 요소가 리소스 선언 내부에서 블록 형태로 여러 번 정의되는 경우다.
# main.tf 수정
resource "aws_security_group" "example" {
name = "example-security-group"
description = "Example security group"
vpc_id. = aws_vpc.main.id
ingress {
from_port = 22
to_port = 22
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
ingress {
from_port = 443
to_port = 443
protocol = "tcp"
ipv6_cidr_blocks = ["::/0"]
}
}- 리소스 내의 블록 속성(Attributes as Blocks)은 리소스 자체의 반복 선언이 아닌 내부 속성 요소 중 블록으로 표현되는 부분에 대해서만 반복 구문을 사용해야 하므로, 이때 dynamic 블록을 사용해 동적인 블록을 생성 할 수 있다.
- dynamic 블록을 작성하려면, 기존 블록의 속성 이름을 dynamic 블록의 이름으로 선언하고 기존 블록 속성에 정의되는 내용을 content 블록에 작성한다.
- 반복 선언에 사용되는 반복문 구문은 for_each를 사용한다. 기존 for_each 적용 시 each 속성에 key, value가 적용되었다면 dynamic에서는 dynamic에 지정한 이름에 대해 속성이 부여된다.
dynamic 블록 활용 예

# archive 프로바이더(링크)의 archive_file에 source 블록 선언을 반복
## main.tf 수정
data "archive_file" "dotfiles" {
type = "zip"
output_path = "${path.module}/dotfiles.zip"
source {
content = "hello a"
filename = "${path.module}/a.txt"
}
source {
content = "hello b"
filename = "${path.module}/b.txt"
}
source {
content = "hello c"
filename = "${path.module}/c.txt"
}
}
# 리소스 내에 반복 선언 구성을 dynamic 블록으로 재구성
## main.tf
variable "names" {
default = {
a = "hello a"
b = "hello b"
c = "hello c"
}
}
data "archive_file" "dotfiles" {
type = "zip"
output_path = "${path.module}/dotfiles.zip"
dynamic "source" {
for_each = var.names
content {
content = source.value
filename = "${path.module}/${source.key}.txt"
}
}
}
[실습3] 반복문
IAM 사용자 3명 생성
# 사용자 1명 생성
## main.tf 수정
provider "aws" {
region = "us-east-2"
}
resource "aws_iam_user" "example" {
name = "neo"
}- 불가능한 방법
[불가능한 방법]
# 테라폼 자체에 절차 논리가 없기 때문에 다음과 같은 동작은 불가
for (i = 0; i < 3; i++) {
resource "aws_iam_user" "example" {
name = "neo"
}
}
# 사용법은 옳으나, 특정 리소스 유형에 따라
# IAM 같이 중복되는 이름을 사용할수 없는 경우에도 불가
resource "aws_iam_user" "example" {
count = 3
name = "neo"
}- 가능한 방법으로 다시 수정후 진행
# 신규 폴더 생성후 작업
mkdir iam-count-for && cd iam-count-for
# count.index 를 사용하여 반복문 안에 있는 각각의 반복 ieration 을 가리키는 인덱스를 얻을 수 있음
# iam.tf 생성
provider "aws" {
region = "ap-northeast-2"
}
resource "aws_iam_user" "myiam" {
count = 3
name = "myuser.${count.index}"
}# 테라폼 초기화 및 확인
terraform init && terraform plan
...
# aws_iam_user.myiam[0] will be created
# aws_iam_user.myiam[1] will be created
# aws_iam_user.myiam[2] will be created
# 실행
terraform apply -auto-approve
# 확인
terraform state list
aws_iam_user.myiam[0]
aws_iam_user.myiam[1]
aws_iam_user.myiam[2]
terraform console
>
-----------------
aws_iam_user.myiam
aws_iam_user.myiam[0]
aws_iam_user.myiam[1].name
exit
-----------------

# IAM User 삭제
terraform destroy -auto-approve
aws iam list-users | jqcount 입력 변수를 통해 IAM 사용자 생성
# 입력 변수 코드 생성
## variables.tf 생성
variable "user_names" {
description = "Create IAM users with these names"
type = list(string)
default = ["gasida", "akbun", "ssoon"]
}- 테라폼에서 count 와 함께 배열 조회 구문과 length 함수를 사용해서 사용자들 생성 가능
- 배열 조회 구문 Array lookup syntax
- ARRAY[<INDEX>]
- 예를 들어 다음은 var.user_names 의 인덱스 1에서 요소를 찾는 방법
- var.user_names[1]
- length (내장) 함수 built-on function
- length(<ARRAY>)
- 주어진 ARRAY 의 항목 수를 반환하는 함수. 문자열 및 맵을 대상으로도 동작
- 배열 조회 구문 Array lookup syntax
# 리소스에 count를 사용한후 에는 하나의 리소스가 아니라 리소스의 배열이 된다
# iam.tf 수정
provider "aws" {
region = "ap-northeast-2"
}
resource "aws_iam_user" "myiam" {
count = length(var.user_names)
name = var.user_names[count.index]
}- aws_iam_user.myiam 은 이제 IAM 사용자의 배열이므로 표준 구문을 사용하여
해당 리소스인 <PROVIDER>_<TYPE>.<NAME>.<ATTRIBUTE> 에서 속성을 읽은 대신
배열에서 인덱스를 지정해서 IAM 사용자를 명시해야합니다.
# IAM 사용자 한명의 ARN과 사용자 전체의 ARN 을 출력 변수 outputs 으로 제공
# IAM 사용자 전체의 ARN을 원하면 인덱스 대신 스플랫 splat 연산자인 * 를 사용
## output.tf 생성
output "first_arn" {
value = aws_iam_user.myiam[0].arn
description = "The ARN for the first user"
}
output "all_arns" {
value = aws_iam_user.myiam[*].arn
description = "The ARNs for all users"
}




count 제약사항
1. 전체 리소스를 반복할 수는 있지만 리소스 내에서 인라인 블록을 반복할 수는 없다.
# 예시 aws_autoscaling_group
resource "aws_autoscaling_group" "example" {
### 리소스 블록 ###
launch_configuration = aws_launch_configuration.example.name
vpc_zone_identifier = data.aws_subnets.default.ids
target_group_arns = [aws_lb_target_group.asg.arn]
health_check_type = "ELB"
min_size = var.min_size
max_size = var.max_size
tag {
### 인라인 블록 ###
key = "Name"
value = var.cluster_name
propagate_at_launch = true
}
}- 각각의 tag 를 사용하려면 key, value, propagate_at_launch 에 대한 값으로 새 인라인 블록을 만들어야 합니다.
- 따라서 count 매개변수를 사용해서 이러한 태그를 반복하고 동적인 인라인 tag 블록을 생성하려고 시도할 수도 있지만, 인라인 블록 내에서는 count 사용은 지원하지 않습니다.
2. 배열 중간 값을 변경할때
# variables.tf를 확인하여 iam을 생성하고
variable "user_names" {
description = "Create IAM users with these names"
type = list(string)
default = ["gasida", "akbun", "ssoon"]
}
# variables.tf 파일의 IAM 사용자 제거
## IAM 생성후 배열에서 akbun 사용자를 제거
variable "user_names" {
description = "Create IAM users with these names"
type = list(string)
default = ["gasida", "ssoon"]
}
- 위의 plan을 따라 배열의 중간에 항목을 제거하면 모든 항목이 1칸씩 앞으로 당겨진다는 것을 확인 할수 있다
- 테라폼이 인덱스 번호를 리소스 식별자로 보기 때문에 ‘인덱스 1에서는 계정 생성
인덱스2에서는 계정 삭제한다 라고 해석 - 즉 count 사용 시 목록 중간 항목을 제거하면 테라폼은 해당 항목 뒤에 있는 모든 리소스를 삭제한 다음 해당 리소스를 처음부터 다시 만듬.


# 이후 IAM 삭제
terraform destroy -auto-approve
aws iam list-users | jqfor_each
for_each 표현식을 사용하면 리스트 lists, 집합 sets, 맵 maps 를 사용하여 전체 리소스의 여러 복사본 또는 리소스 내 인라인 블록의 여러 복사본, 모듈의 복사본을 생성 할 수 있음
- for_each 를 사용하여 리소스의 여러 복사본을 만드는 구문은 다음과 같다
resource "<PROVIDER>_<TYPE>" "<NAME>" {
for_each = <COLLECTION>
[CONFIG ...]
}- COLLECTION 은 루프를 처리할 집합 sets 또는 맵 maps
- 리소스에 for_each 를 사용할 때에는 리스트는 지원하지 않음
- 그리고 CONFIG 는 해당 리소스와 관련된 하나 이상의 인수로 구성되는데 CONFIG 내에서 each.key 또는 each.value 를 사용하여 COLLECTION 에서 현재 항목의 키와 값에 접근할 수 있습니다.
예시
- var.user_names 리스트를 집합(set)으로 변환하기 위해 toset 사용.
for_each 는 리소스에 사용될 때는 집합 set, 맵 map만 지원. - for_each 가 이 집합을 반복하면 each.value 에서 각 사용자 이름을 사용
# for_each 를 사용하여 3명의 IAM 사용자를 생성하는 예시
# 일반적으로는 each.key 는 키/값 쌍 맵에서만 사용가능하지만
# 사용자 이름은 each.key 에서도 사용할 수 있습니다.
## iam.tf 수정
provider "aws" {
region = "ap-northeast-2"
}
resource "aws_iam_user" "myiam" {
for_each = toset(var.user_names)
name = each.value
}
## variables.tf 수정 (akbun 사용자 다시 추가)
variable "user_names" {
description = "Create IAM users with these names"
type = list(string)
default = ["gasida", "akbun", "ssoon"]
}- for_each 를 사용한 후에는 하나의 리소스 또는 count 를 사용한 것과 같은 리소스 배열이 되는 것이 아니리
리소스 맵 list into a set 이 됩니다.
# 위의 의미를 확인하려면 원래의 outputs 을 제거하고 새로운 all_users 출력 변수를 추가하자
# output.tf 수정
output "all_users" {
value = aws_iam_user.myiam
}


- for_each 를 사용해 리소스를 맵으로 처리하면 컬렉션 중간의 항목도 안전하게 제거할 수 있어서
count 로 리소스를 배열 처리보다 이점이 큽니다.
# 다시 akbun 사용자 삭제
# variables.tf 수정
variable "user_names" {
description = "Create IAM users with these names"
type = list(string)
default = ["gasida", "ssoon"]
}



# 따라서 리소스의 구별되는 여러 복사본을 만들 때는
# count 대신 for_each 를 사용하는 것이 바람직한것을 확인할수 있다
## 확인 후 삭제
terraform destroy -auto-approve
aws iam list-users | jq
'공부하면서 > Terraform' 카테고리의 다른 글
| [T1012] 3주차 - 테라폼 기본 사용 3/3 (terraform_data, moved, 환경변수) (0) | 2023.07.22 |
|---|---|
| [T1012] 3주차 - 테라폼 기본 사용 3/3 (조건문,함수,프로비저너) (0) | 2023.07.21 |
| [T1012] 2주차 - 테라폼 기본 사용 2/3 (출력 output) (0) | 2023.07.15 |
| [T1012] 2주차 - 테라폼 기본 사용 2/3 (local 지역 값 + 실습) (1) | 2023.07.15 |
| [T1012] 2주차 - 테라폼 기본 사용 2/3 (데이터 소스 + 실습) (0) | 2023.07.15 |